on
Nim
Nim is a young and exciting imperative programming language that is nearing its 1.0 release. My main motivation for using Nim is its performance / productivity ratio and the joy of programming in Nim. In this guide I’m going to show you how I start a Nim project.
For this purpose we will write a small interpreter for the brainfuck language. While Nim is a practical language with many interesting features, brainfuck is the opposite: It’s impractical to write in and its features consist of 8 single-character commands. Still, brainfuck is great for us, since its extreme simplicity makes it easy to write an interpreter for it. Later we will even write a high-performance compiler that transforms brainfuck programs into Nim at compile time. We will put all of this into a nimble package and publish it online.
Installation
Installing Nim is straightforward, you can follow the official
instructions. Binaries for Windows are
provided. On other operating systems you can run the build.sh script to
compile the generated C code, which should take less than 1 minute on a modern
system.
This brings us to the first interesting fact about Nim: It compiles to C primarily (C++, ObjectiveC and even JavaScript as well) and then uses the highly optimizing C compiler of your choice to generate the actual program. You get to benefit from the mature C ecosystem for free.
If you opt for bootstrapping the Nim compiler, which is written exclusively in Nim itself, you get to witness the compiler build itself with a few simple steps (in less than 2 minutes):
$ git clone https://github.com/nim-lang/Nim
$ cd Nim
$ git clone --depth 1 https://github.com/nim-lang/csources
$ cd csources && sh build.sh
$ cd ..
$ bin/nim c koch
$ ./koch boot -d:release
This way you get a development version of Nim. To keep it up to date these two steps should be enough:
$ git pull
$ ./koch boot -d:release
If you haven’t done so already, now is a good time to install git as well.
Most nimble packages are available on github, so we will need git to get
them. On a Debian based distribution (like Ubuntu) we can install it like this:
$ sudo apt-get install git
After you’ve finished the installation, you should add the nim binary to your
path. If you use bash, this is what to do:
$ echo 'export PATH=$PATH:$your_install_dir/bin' >> ~/.profile
$ source ~/.profile
$ nim
Nim Compiler Version 0.17.3 [Linux: amd64]
Copyright (c) 2006-2017 by Andreas Rumpf
::
nim command [options] [projectfile] [arguments]
Command:
compile, c compile project with default code generator (C)
doc generate the documentation for inputfile
...
If nim reports its version and usage, we’re good to continue. Now the modules
from Nim’s standard library are just an import
away. All other packages can be retrieved with
nimble, Nim’s package manager. Let’s
follow the one-liner installation
instructions:
$ ./koch nimble
Nimble’s binary directory wants to be added to your path as well:
$ echo 'export PATH=$PATH:$HOME/.nimble/bin' >> ~/.profile
$ source ~/.profile
$ nimble update
Downloading Official package list
Success Package list downloaded.
Now we can browse the available nimble packages or search for them on the command line:
$ nimble search docopt
docopt:
url: https://github.com/docopt/docopt.nim (git)
tags: commandline, arguments, parsing, library
description: Command-line args parser based on Usage message
license: MIT
website: https://github.com/docopt/docopt.nim
Let’s install this nice docopt library we found, maybe we’ll need it later:
$ nimble install docopt
...
Verifying dependencies for [email protected]
Installing [email protected]
Success: docopt installed successfully.
Notice how quickly the library is installed (less than 1 second for me). This is another nice effect of Nim. Basically the source code of the library is just downloaded, nothing resembling a shared library is compiled. Instead the library will simply be compiled statically into our program once we use it.
There is Nim editor support for most of the popular editors out there, like Emacs (nim-mode), Vim (nimrod.vim, my choice) and Sublime (NimLime). For the scope of this guide any text editor will do.
Project Setup
Now we’re ready to get our project started:
$ mkdir brainfuck
$ cd brainfuck
First step: To get Hello World on the terminal, we create a hello.nim
with the following content:
echo "Hello World"
We compile the code and run it, first in two separate steps:
$ nim c hello
$ ./hello
Hello World
Then in a single step, by instructing the Nim compiler to conveniently run the resulting binary immediately after creating it:
$ nim c -r hello
Hello World
Let’s make our code do something slightly more complicated, that should take a bit longer to run:
var x = 0
for i in 1 .. 100_000_000:
inc x # increase x, this is a comment btw
echo "Hello World ", x
Now we’re initializing the variable x to 0 and increase it by 1 a whole 100
million times. Try to compile and run it again. Notice how long it takes to run
now. Is Nim’s performance that abysmal? Of course not, quite the opposite!
We’re just currently building the binary in full debug mode, adding checks for
integer overflows, array out of bounds and much more, as well as not optimizing
the binary at all. The -d:release option allows us to switch into release
mode, giving us full speed:
$ nim c hello
$ time ./hello
Hello World 100000000
./hello 2.01s user 0.00s system 99% cpu 2.013 total
$ nim -d:release c hello
$ time ./hello
Hello World 100000000
./hello 0.00s user 0.00s system 74% cpu 0.002 total
That’s a bit too fast actually. The C compiler optimized away the entire for
loop. Oops.
To start a new project nimble init can generate a basic package config file:
$ nimble init brainfuck
Info: In order to initialise a new Nimble package, I will need to ask you
... some questions. Default values are shown in square brackets, press
... enter to use them.
Prompt: Initial version of package? [0.2.0]
Answer:
Prompt: Your name? [Dennis Felsing]
Answer:
Prompt: Package description?
Answer: A brainfuck interpreter
Prompt: Package license? [MIT]
Answer:
Prompt: Lowest supported Nim version? [0.17.3]
Answer: 0.10.0
Success: Nimble file created successfully
The newly created brainfuck.nimble should look like this:
# Package
version = "0.2.0"
author = "Dennis Felsing"
description = "A brainfuck interpreter"
license = "MIT"
# Dependencies
requires "nim >= 0.10.0"
Let’s add the requirement for docopt and the binary we want to create, as described in nimble’s “Creating Package” documentation.
# Package
version = "0.2.0"
author = "Dennis Felsing"
description = "A brainfuck interpreter"
license = "MIT"
bin = @["brainfuck"]
# Dependencies
requires "nim >= 0.10.0"
requires "docopt >= 0.1.0"
Since we have git installed already, we’ll want to keep revisions of our source code and may want to publish them online at some point, let’s initialize a git repository:
$ git init
$ git add brainfuck.nim brainfuck.nimble .gitignore
Where I just initialized the .gitignore file to this:
nimcache/
*.swp
We tell git to ignore vim’s swap files, as well as nimcache directories that
contain the generated C code for our project. Check it out if you’re curious
how Nim compiles to C.
To see what nimble can do, let’s initialize brainfuck.nim, our main program:
echo "Welcome to brainfuck"
We could compile it as we did before for hello.nim, but since we already set
our package up to include the brainfuck binary, let’s make nimble do the
work:
$ nimble build
Verifying dependencies for [email protected]
Info: Dependency on docopt@>= 0.6.5 already satisfied
Verifying dependencies for [email protected]
Building brainfuck/brainfuck using c backend
$ ./brainfuck
Welcome to brainfuck
nimble install can be used to install the binary on our system, so that we can run it from anywhere:
$ nimble install
Verifying dependencies for [email protected]
Info: Dependency on docopt@>= 0.6.5 already satisfied
Verifying dependencies for [email protected]
Installing [email protected]
Building brainfuck/brainfuck using c backend
Success: brainfuck installed successfully.
$ brainfuck
Welcome to brainfuck
This is great for when the program works, but nimble build actually does a
release build for us. That takes a bit longer than a debug build, and leaves
out the checks which are so important during development, so nim c -r brainfuck will be a better fit for now. Feel free to execute our program quite
often during development to get a feeling for how everything works.
Coding
While programming Nim’s documentation comes in handy. If you don’t know where to find what yet, there’s a documentation index, in which you can search.
Let’s start developing our interpreter by changing the brainfuck.nim file:
import os
First we import the os module, so that we can read command line arguments.
let code = if paramCount() > 0: readFile paramStr(1)
else: readAll stdin
paramCount() tells us about the number of command line arguments passed to
the application. If we get a command line argument, we assume it’s a filename,
and read it in directly with readFile paramStr(1). Otherwise we read
everything from the standard input. In both cases, the result is stored in the
code variable, which has been declared immutable with the let keyword.
To see if this works, we can echo the code:
echo code
And try it out:
$ nim c -r brainfuck
...
Welcome to brainfuck
I'm entering something here and it is printed back later!
I'm entering something here and it is printed back later!
After you’ve entered your “code” finish up with a newline and ctrl-d. Or you
can pass in a filename, everything after nim c -r brainfuck is passed as
command line arguments to the resulting binary:
$ nim c -r brainfuck .gitignore
...
Welcome to brainfuck
nimcache/
*.swp
On we go:
var
tape = newSeq[char]()
codePos = 0
tapePos = 0
We declare a few variables that we’ll need. We have to remember our current
position in the code string (codePos) as well as on the tape (tapePos).
Brainfuck works on an infinitely growing tape, which we represent as a seq
of chars. Sequences are Nim’s dynamic length arrays, other than with newSeq
they can also be initialized using var x = @[1, 2, 3].
Let’s take a moment to appreciate that we don’t have to specify the type of our variables, it is automatically inferred. If we wanted to be more explicit, we could do so:
var
tape: seq[char] = newSeq[char]()
codePos: int = 0
tapePos: int = 0
Next we write a small procedure, and call it immediately afterwards:
proc run(skip = false): bool =
echo "codePos: ", codePos, " tapePos: ", tapePos
discard run()
There are a few things to note here:
- We pass a
skipparameter, initialized tofalse. - Obviously the parameter must be of type
boolthen. - The return type is
boolas well, but we return nothing? Every result is initialized to binary 0 by default, meaning we returnfalse. - We can use the implicit
resultvariable in every proc with a result and setresult = true. - Control flow can be changed by using
return trueto return immediately. - We have to explicitly
discardthe returned bool value when callingrun(). Otherwise the compiler complains withbrainfuck.nim(16, 3) Error: value of type 'bool' has to be discarded. This is to prevent us from forgetting to handle the result.
Before we continue, let’s think about the way brainfuck works. Some of this may
look familiar if you’ve encountered Turing machines before. We have an input
string code and a tape of chars that can grow infinitely in one
direction. These are the 8 commands that can occur in the input string, every
other character is ignored:
| Op | Meaning | Nim equivalent |
|---|---|---|
> | move right on tape | inc tapePos |
< | move left on tape | dec tapePos |
+ | increment value on tape | inc tape[tapePos] |
- | decrement value on tape | dec tape[tapePos] |
. | output value on tape | stdout.write tape[tapePos] |
, | input value to tape | tape[tapePos] = stdin.readChar |
[ | if value on tape is \0, jump forward to command after matching ] | |
] | if value on tape is not \0, jump back to command after matching [ |
With this alone, brainfuck is one of the simplest Turing complete programming languages.
The first 6 commands can easily be converted into a case distinction in Nim:
proc run(skip = false): bool =
case code[codePos]
of '+': inc tape[tapePos]
of '-': dec tape[tapePos]
of '>': inc tapePos
of '<': dec tapePos
of '.': stdout.write tape[tapePos]
of ',': tape[tapePos] = stdin.readChar
else: discard
We are handling a single character from the input so far, let’s make this a loop to handle them all:
proc run(skip = false): bool =
while tapePos >= 0 and codePos < code.len:
case code[codePos]
of '+': inc tape[tapePos]
of '-': dec tape[tapePos]
of '>': inc tapePos
of '<': dec tapePos
of '.': stdout.write tape[tapePos]
of ',': tape[tapePos] = stdin.readChar
else: discard
inc codePos
Let’s try a simple program, like this:
$ echo ">+" | nim -r c brainfuck
Welcome to brainfuck
Traceback (most recent call last)
brainfuck.nim(26) brainfuck
brainfuck.nim(16) run
Error: unhandled exception: index out of bounds [IndexError]
Error: execution of an external program failed
What a shocking result, our code crashes! What did we do wrong? The tape is
supposed to grow infinitely, but we haven’t increased its size at all! That’s
an easy fix right above the case:
if tapePos >= tape.len:
tape.add '\0'
The last 2 commands, [ and ] form a simple loop. We can encode them into
our code as well:
proc run(skip = false): bool =
while tapePos >= 0 and codePos < code.len:
if tapePos >= tape.len:
tape.add '\0'
if code[codePos] == '[':
inc codePos
let oldPos = codePos
while run(tape[tapePos] == '\0'):
codePos = oldPos
elif code[codePos] == ']':
return tape[tapePos] != '\0'
elif not skip:
case code[codePos]
of '+': inc tape[tapePos]
of '-': dec tape[tapePos]
of '>': inc tapePos
of '<': dec tapePos
of '.': stdout.write tape[tapePos]
of ',': tape[tapePos] = stdin.readChar
else: discard
inc codePos
If we encounter a [ we recursively call the run function itself, looping
until the corresponding ] lands on a tapePos that doesn’t have \0 on the
tape.
If you’re on Nim 0.11 or a newer version, you’ll run into another problem: The
inc and dec procs for chars have overflow (and underflow) checks. This
means that when we have the character \0 and decrement it, we end up with a
runtime error! Instead, in brainfuck, we want to wrap around and get \255
instead. We cold use a uint8 instead of a char, because unsigned ints wrap
around in Nim. But then we have to convert that uint8 to a char sometimes
and the other way around. A more convenient way is to define our own,
non-overflow-checking xinc and xdec procs:
{.push overflowchecks: off.}
proc xinc(c: var char) = inc c
proc xdec(c: var char) = dec c
{.pop.}
We use Nim’s pragma system to disable overflow checks just for this part of the code, not touching the settings for the rest of the program. Now of course two cases have to change:
of '+': xinc tape[tapePos]
of '-': xdec tape[tapePos]
And that’s it. We have a working brainfuck interpreter now. To test it, we
create an examples directory containing these 3 files:
helloworld.b, rot13.b,
mandelbrot.b.
$ nim -r c brainfuck examples/helloworld.b
Welcome to brainfuck
Hello World!
$ ./brainfuck examples/rot13.b
Welcome to brainfuck
You can enter anything here!
Lbh pna ragre nalguvat urer!
ctrl-d
$ ./brainfuck examples/mandelbrot.b
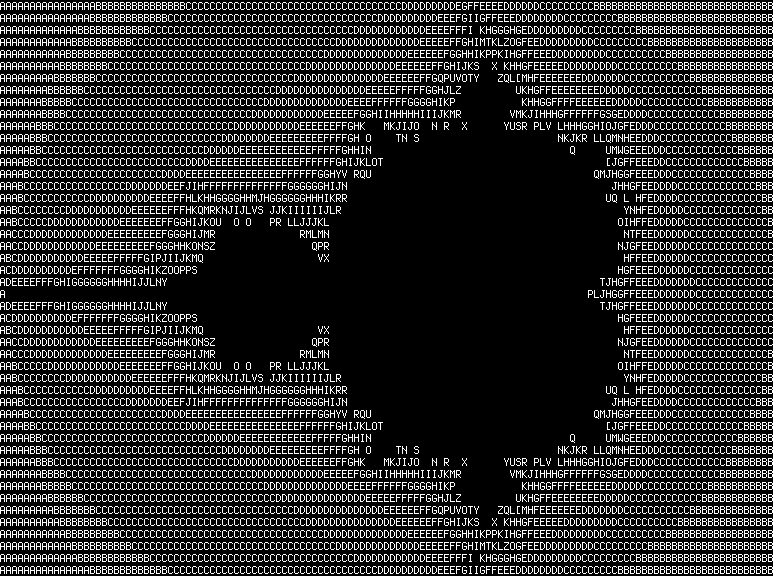
With the last one you will notice how slow our interpreter is. Compiling with
-d:release gives a nice speedup, but still takes about 90 seconds on my
machine to draw the Mandelbrot set. To achieve a great speedup, later on we
will compile brainfuck to Nim instead of interpreting it. Nim’s metaprogramming
capabilities are perfect for this.
But let’s keep it simple for now. Our interpreter is working, now we can turn
our work into a reusable library. All we have to do is surround our code with a
big proc:
proc interpret*(code: string) =
var
tape = newSeq[char]()
codePos = 0
tapePos = 0
proc run(skip = false): bool =
...
discard run()
when isMainModule:
import os
echo "Welcome to brainfuck"
let code = if paramCount() > 0: readFile paramStr(1)
else: readAll stdin
interpret code
Note that we also added a * to the proc, which indicates that it is exported
and can be accessed from outside of our module. Everything else is hidden.
At the end of the file we still kept the code for our binary. when isMainModule ensures that this code is only compiled when this module is the
main one. After a quick nimble install our brainfuck library can be used from
anywhere on your system, just like this:
import brainfuck
interpret "++++++++[>++++[>++>+++>+++>+<<<<-]>+>+>->>+[<]<-]>>.>---.+++++++..+++.>>.<-.<.+++.------.--------.>>+.>++."
Looking good! At this point we could share the code with others already, but let’s add some documentation first:
proc interpret*(code: string) =
## Interprets the brainfuck `code` string, reading from stdin and writing to
## stdout.
...
nim doc brainfuck builds the documentation, which you can see
online in its full glory.
Metaprogramming
As I said before, our interpreter is still pretty slow for the mandelbrot program. Let’s write a procedure that creates Nim code AST at compile time instead:
import macros
proc compile(code: string): PNimrodNode {.compiletime.} =
var stmts = @[newStmtList()]
template addStmt(text): typed =
stmts[stmts.high].add parseStmt(text)
addStmt "var tape: array[1_000_000, char]"
addStmt "var tapePos = 0"
for c in code:
case c
of '+': addStmt "xinc tape[tapePos]"
of '-': addStmt "xdec tape[tapePos]"
of '>': addStmt "inc tapePos"
of '<': addStmt "dec tapePos"
of '.': addStmt "stdout.write tape[tapePos]"
of ',': addStmt "tape[tapePos] = stdin.readChar"
of '[': stmts.add newStmtList()
of ']':
var loop = newNimNode(nnkWhileStmt)
loop.add parseExpr("tape[tapePos] != '\\0'")
loop.add stmts.pop
stmts[stmts.high].add loop
else: discard
result = stmts[0]
echo result.repr
The template addStmt is just there to reduce boilerplate. We could also
explicitly write the same operation at each position that currently uses
addStmt. (And that’s exactly what a template does!) parseStmt turns a piece
of Nim code from a string into its corresponding AST, which we store in a list.
Most of the code is similar to the interpreter, except we’re not executing the
code now, but generating it, and adding it to a list of statements. [ and ]
are more complicated: They get translated into a while loop surrounding the
code inbetween.
We’re cheating a bit here because we use a fixed size tape now and don’t
check for under- and overflows anymore. This is mainly for the sake of
simplicity. To see what this code does, the last line, namely echo result.repr prints the Nim code we generated.
Try it out by calling it inside a static block, which forces execution at
compile time:
static:
discard compile "+>+[-]>,."
During compilation the generated code is printed:
var tape: array[1000000, char]
var codePos = 0
var tapePos = 0
xinc tape[tapePos]
inc tapePos
xinc tape[tapePos]
while tape[tapePos] != '\0':
xdec tape[tapePos]
inc tapePos
tape[tapePos] = stdin.readChar
stdout.write tape[tapePos]
Generally useful for writing macros is the dumpTree macro, which prints the
AST of a piece of code (actual one, not as a string), for example:
import macros
dumpTree:
while tape[tapePos] != '\0':
inc tapePos
This shows us the following Tree:
StmtList
WhileStmt
Infix
Ident !"!="
BracketExpr
Ident !"tape"
Ident !"tapePos"
CharLit 0
StmtList
Command
Ident !"inc"
Ident !"tapePos"
That’s how I knew that we would need a StmtList, for example. When you do
metaprogramming in Nim, it’s generally a good idea to use dumpTree and print
out the AST of the code you want to generate.
Macros can be used to insert the generated code into a program directly:
macro compileString*(code: string): typed =
## Compiles the brainfuck `code` string into Nim code that reads from stdin
## and writes to stdout.
compile code.strval
macro compileFile*(filename: string): typed =
## Compiles the brainfuck code read from `filename` at compile time into Nim
## code that reads from stdin and writes to stdout.
compile staticRead(filename.strval)
We can now compile the mandelbrot program into Nim easily:
proc mandelbrot = compileFile "examples/mandelbrot.b"
mandelbrot()
Compiling with full optimizations takes quite long now (about 4 seconds), because the mandelbrot program is huge and GCC needs some time to optimize it. In return the program runs in just 1 second:
$ nim -d:release c brainfuck
$ ./brainfuck
Compiler settings
By default Nim compiles its intermediate C code with GCC, but clang usually
compiles faster and may even yield more efficient code. It’s always worth a
try. To compile once with clang, use nim -d:release --cc:clang c brainfuck. If
you want to keep compiling brainfuck.nim with clang, create a
brainfuck.nim.cfg file with the content cc = clang. To change the default
backend compiler, edit config/nim.cfg in Nim’s directory.
While we’re talking about changing default compiler options. The Nim compiler
is quite talky at times, which can be disabled by setting hints = off in the
Nim compiler’s config/nim.cfg. One of the more unexpected compiler warnings
even warns you if you use l (lowercase L) as an identifier, because it may look
similar to 1 (one):
a.nim(1, 4) Warning: 'l' should not be used as an identifier; may look like '1' (one) [SmallLshouldNotBeUsed]
If you’re not a fan of this, a simple warning[SmallLshouldNotBeUsed] = off
suffices to make the compiler shut up.
Another advantage of Nim is that we can use debuggers with C support, like GDB.
Simply compile your program with nim c --linedir:on --debuginfo c brainfuck and
gdb ./brainfuck can be used to debug your program.
Command line argument parsing
So far we’ve been parsing the command line argument by hand. Since we already installed the docopt.nim library before, we can use it now:
when isMainModule:
import docopt, tables, strutils
proc mandelbrot = compileFile("examples/mandelbrot.b")
let doc = """
brainfuck
Usage:
brainfuck mandelbrot
brainfuck interpret [<file.b>]
brainfuck (-h | --help)
brainfuck (-v | --version)
Options:
-h --help Show this screen.
-v --version Show version.
"""
let args = docopt(doc, version = "brainfuck 1.0")
if args["mandelbrot"]:
mandelbrot()
elif args["interpret"]:
let code = if args["<file.b>"]: readFile($args["<file.b>"])
else: readAll stdin
interpret(code)
The nice thing about docopt is that the documentation functions as the specification. Pretty simple to use:
$ nimble install
...
brainfuck installed successfully.
$ brainfuck -h
brainfuck
Usage:
brainfuck mandelbrot
brainfuck interpret [<file.b>]
brainfuck (-h | --help)
brainfuck (-v | --version)
Options:
-h --help Show this screen.
-v --version Show version.
$ brainfuck interpret examples/helloworld.b
Hello World!
Refactoring
Since our project is growing, we move the main source code into a src
directory and add a tests directory, which we will soon need, resulting in a
final directory structure like this:
$ tree
.
├── brainfuck.nimble
├── examples
│ ├── helloworld.b
│ ├── mandelbrot.b
│ └── rot13.b
├── license.txt
├── readme.md
├── src
│ └── brainfuck.nim
└── tests
├── all.nim
├── compile.nim
├── interpret.nim
└── nim.cfg
This also requires us to change the nimble file:
srcDir = "src"
bin = @["brainfuck"]
To improve reusability of our code, we turn to refactoring it. The main concern is that we always read from stdin and write to stdout.
Instead of accepting just a code: string as its parameter, we extend the
interpret procedure to also receive an input and output stream. This uses the
streams module that provides FileStreams
and StringStreams:
## :Author: Dennis Felsing
##
## This module implements an interpreter for the brainfuck programming language
## as well as a compiler of brainfuck into efficient Nim code.
##
## Example:
##
## .. code:: nim
## import brainfuck, streams
##
## interpret("++++++++[>++++[>++>+++>+++>+<<<<-]>+>+>->>+[<]<-]>>.>---.+++++++..+++.>>.<-.<.+++.------.--------.>>+.>++.")
## # Prints "Hello World!"
##
## proc mandelbrot = compileFile("examples/mandelbrot.b")
## mandelbrot() # Draws a mandelbrot set
import streams
proc interpret*(code: string; input, output: Stream) =
## Interprets the brainfuck `code` string, reading from `input` and writing
## to `output`.
##
## Example:
##
## .. code:: nim
## var inpStream = newStringStream("Hello World!\n")
## var outStream = newFileStream(stdout)
## interpret(readFile("examples/rot13.b"), inpStream, outStream)
I’ve also added some module wide documentation, including example code for how our library can be used. Take a look at the resulting documentation.
Most of the code stays the same, except the handling of brainfuck operations
. and ,, which now use output instead of stdout and input instead of
stdin:
of '.': output.write tape[tapePos]
of ',': tape[tapePos] = input.readCharEOF
What is this strange readCharEOF doing there instead of readChar? On many
systems EOF (end of file) means -1. Our brainfuck programs actively use
this. This means our brainfuck programs might actually not run on all systems.
Meanwhile the streams module strives to be platform independent, so it returns
a 0 if we have reached EOF. We use readCharEOF to convert this into a
-1 for brainfuck explicitly:
proc readCharEOF*(input: Stream): char =
result = input.readChar
if result == '\0': # Streams return 0 for EOF
result = '\255' # BF assumes EOF to be -1
At this point you may notice that the order of identifier declarations matters
in Nim. If you declare readCharEOF below interpret, you can not use it in
interpret. I personally try to adhere to this, as it creates a hierarchy from
simple code to more complex code in each module. If you still want to
circumvent this , split declaration and definition of readCharEOF by adding
this declaration above interpret:
proc readCharEOF*(input: Stream): char
The code to use the interpreter as conveniently as before is pretty simple:
proc interpret*(code, input: string): string =
## Interprets the brainfuck `code` string, reading from `input` and returning
## the result directly.
var outStream = newStringStream()
interpret(code, input.newStringStream, outStream)
result = outStream.data
proc interpret*(code: string) =
## Interprets the brainfuck `code` string, reading from stdin and writing to
## stdout.
interpret(code, stdin.newFileStream, stdout.newFileStream)
Now the interpret procedure can be used to return a string. This will be
important for testing later:
let res = interpret(readFile("examples/rot13.b"), "Hello World!\n")
interpret(readFile("examples/rot13.b")) # with stdout
For the compiler the cleanup is a bit more complicated. First we have to take
the input and output as strings, so that the user of this proc can use any
stream they want:
proc compile(code, input, output: string): PNimrodNode {.compiletime.} =
Two additional statements are necessary to initialize the input and output streams to the passed strings:
addStmt "var inpStream = " & input
addStmt "var outStream = " & output
Of course now we have to use outStream and inpStream instead of stdout and
stdin, as well as readCharEOF instead of readChar. Note that we can
directly reuse the readCharEOF procedure from the interpreter, no need to
duplicate code:
of '.': addStmt "outStream.write tape[tapePos]"
of ',': addStmt "tape[tapePos] = inpStream.readCharEOF"
We also add a statement that will abort compilation with a nice error message if the user of our library uses it wrongly:
addStmt """
when not compiles(newStringStream()):
static:
quit("Error: Import the streams module to compile brainfuck code", 1)
"""
To connect the new compile procedure to a compileFile macro that uses
stdout and stdin again, we can write:
macro compileFile*(filename: string): typed =
compile(staticRead(filename.strval),
"stdin.newFileStream", "stdout.newFileStream")
To read from an input string and write back to an output string:
macro compileFile*(filename: string; input, output: untyped): typed =
result = compile(staticRead(filename.strval),
"newStringStream(" & $input & ")", "newStringStream()")
result.add parseStmt($output & " = outStream.data")
This unwieldy code allows us to write a compiled rot13 procedure like this,
connecting input string and result to the compiled program:
proc rot13(input: string): string =
compileFile("../examples/rot13.b", input, result)
echo rot13("Hello World!\n")
I did the same for compileString for convenience. You can check out the full
code of brainfuck.nim on
Github.
Testing
There are two main ways of testing code in Nim that you will run across. For
small pieces of code you can simply use asserts inside a when isMainModule
block at the end of the file. This ensures that the testing code will not be
executed when the module is used as a library.
Regular assertions can be turned off in Nim with --assertions:off, which is
automatically set when we compile a release build. For this reason instead of
assert we use doAssert, which will not be optimized away even in release
builds. You will find tests like this at the end of many of the standard
library’s modules:
when isMainModule:
doAssert align("abc", 4) == " abc"
doAssert align("a", 0) == "a"
doAssert align("1232", 6) == " 1232"
doAssert align("1232", 6, '#') == "##1232"
For a bigger project the unittest module comes in handy.
We split up the tests into 3 files in the tests/ directory:
tests/interpret.nim tests the interpreter. We define a new test suite,
containing two testers, each checking the resulting strings:
import unittest, brainfuck
suite "brainfuck interpreter":
test "interpret helloworld":
let helloworld = readFile("examples/helloworld.b")
check interpret(helloworld, input = "") == "Hello World!\n"
test "interpret rot13":
let rot13 = readFile("examples/rot13.b")
let conv = interpret(rot13, "How I Start\n")
check conv == "Ubj V Fgneg\n"
check interpret(rot13, conv) == "How I Start\n"
Similarly for tests/compile.nim to test our compiler:
import unittest, brainfuck, streams
suite "brainfuck compiler":
test "compile helloworld":
proc helloworld: string =
compileFile("../examples/helloworld.b", "", result)
check helloworld() == "Hello World!\n"
test "compile rot13":
proc rot13(input: string): string =
compileFile("../examples/rot13.b", input, result)
let conv = rot13("How I Start\n")
check conv == "Ubj V Fgneg\n"
check rot13(conv) == "How I Start\n"
Note how we have to read the examples from ../examples/ with the compiler,
instead of examples/ with the interpreter. The reason for this is that the
compiler’s staticRead opens the files relative to the location of our file,
which resides in tests/.
To combine both tests we can simply run nimble test, which automatically builds and executes the source files in the tests directory:
$ nimble test
Executing task test in /home/d067158/git/nim-brainfuck/brainfuck.nimble
Verifying dependencies for [email protected]
Info: Dependency on docopt@>= 0.1.0 already satisfied
Verifying dependencies for [email protected]
Compiling /home/d067158/git/nim-brainfuck/tests/compile.nim (from package brainfuck) using c backend
Hint: used config file '/media/nim/config/nim.cfg' [Conf]
[Suite] brainfuck compiler
[OK] compile helloworld
[OK] compile rot13
Success: Execution finished
Verifying dependencies for [email protected]
Info: Dependency on docopt@>= 0.1.0 already satisfied
Verifying dependencies for [email protected]
Compiling /home/d067158/git/nim-brainfuck/tests/interpret.nim (from package brainfuck) using c backend
Hint: used config file '/media/nim/config/nim.cfg' [Conf]
[Suite] brainfuck interpreter
[OK] interpret helloworld
[OK] interpret rot13
Success: Execution finished
Success: All tests passed
Great success, our library works! With this we have a fully fledged library, binary and testing framework.
Time to publish everything on
Github and submit a pull request to
have brainfuck included in the nimble
packages. Once the package is accepted
you can find it in the official list and
use nimble to search for it and install it:
$ nimble search brainfuck
brainfuck:
url: https://github.com/def-/nim-brainfuck.git (git)
tags: library, binary, app, interpreter, compiler, language
description: A brainfuck interpreter and compiler
license: MIT
website: https://github.com/def-/nim-brainfuck
$ nimble install brainfuck
Continuous Integration
CircleCI can be used with Nim for continuous integration, so that our tests are compiled and run whenever a new commit is pushed to Github. Since CircleCI does not know about Nim itself, we have to teach it how to bootstrap the compiler:
dependencies:
override:
- |
if [ ! -x ~/nim/bin/nim ]; then
git clone -b devel --depth 1 https://github.com/nim-lang/Nim ~/nim/
git clone --depth 1 https://github.com/nim-lang/csources ~/nim/csources/
cd ~/nim/csources; sh build.sh; cd ..; rm -rf csources
ln -fs ~/nim/bin/nim ~/bin/nim
bin/nim c koch; ./koch boot -d:release; ./koch nimble
ln -fs ~/nim/bin/nimble ~/bin/nimble
else
cd ~/nim; git fetch origin
git merge FETCH_HEAD | grep "Already up-to-date" || (bin/nim c koch; ./koch boot -d:release; ./koch nimble)
fi
cache_directories:
- "~/bin/"
- "~/nim/"
- "~/.nimble/"
compile:
override:
- nimble build -y
This automatically keeps the compiler up to date. If you want to use the most
recently released version of Nim instead of the development build, use the
master branch instead of devel in the git clone call. Running the
tests is straightfoward now:
test:
override:
- nimble test -y
The build status badge  can be added to the
can be added to the readme.md like this:
# Brainfuck for Nim [](https://circleci.com/gh/def-/nim-brainfuck)
See the Github page again for the final result and the CircleCI page for the actual builds.
Conclusion
This is the end of our tour through the Nim ecosystem, I hope you enjoyed it and found it as interesting as it was for me to write it.
If you still want to learn more about Nim, I have recently written about what is special about Nim and what makes Nim practical, and have an extensive collection of small programs.
If you’re interested in a more traditional start into Nim, the official tutorial and Nim by Example can guide you.
The Nim community is very welcoming and helpful. Thanks to everyone who had suggestions and found bugs in this document, especially Flaviu Tamas, Andreas Rumpf and Dominik Picheta.

Nim
Dennis is an active contributor to the Nim language while working on his Master's thesis at KIT. There he worked on research developing a new method for Regression Verification and teaching programming paradigms (Haskell, lambda calculus, type inference, Prolog, Scala, etc.). He also develops and runs DDNet, a unique cooperative 2D game.